
Challenge A. Binarization for Southeast Asian Palm Leaf Manuscripts
A.1 Description and goals
Binarization is widely applied as the first pre-processing step in image document analysis [2]. Binarization is a common starting point for document image analysis. The pipeline converts grey level image values into binary representation for background and foreground, or in more specific definition, text and non-text, which is then feed into further document processing task such as text line segmentation and optical character recognition (OCR). The performance of binarization techniques has a great impact and directly affects the performance of the recognition task [3]. Non optimal binarization method produces unrecognizable characters with noises [1]. Many binarization methods have been reported. These methods have been tested and evaluated on different types of document collections. A binarization method that performs well for one document collection, may not necessarily be applied to another document collection with the same performance [2]. For this reason, there is always a need to evaluate the new binarization methods for a new document collection that has different characteristics, for example the historical archive documents. The objective of this challenge is for the participants to propose a binarization technique specifically suited for ancient palm leaf documents with degradations and noises.
A.2 Dataset
The palm leaf manuscript datasets for binarization task are presented in Table 1. One ground truth binarized image is provided for each image. The binarized ground truth images for Khmer manuscripts were generated manually with the help of a photo editing software (Fig. 2). A pressure sensitive tip stylus is used to trace each text stroke by keeping the original size of the stroke width [4]. For the manuscripts from Bali, the binarized ground truth images have been created with a semi-automatic scheme [5–7,8] (Fig. 1). The binarized ground truth images for Sundanese manuscripts were manually [9] generated by using PixLabeler [10] (Fig. 3). The training set with the ground truth will also be provided for supervised learning methods.
|
Manuscripts |
Train |
Test |
DataSet |
|
Balinese |
50 pages |
50 pages |
Extracted from AMADI_LontarSet [5,8] |
|
Khmer |
23 pages |
23 pages |
Extracted from EFEO [4] |
|
Sundanese |
31 pages |
30 pages |
Extracted from Sunda Dataset ICDAR2017 [9] |
Table 1 : Palm leaf manuscript datasets for binarization task

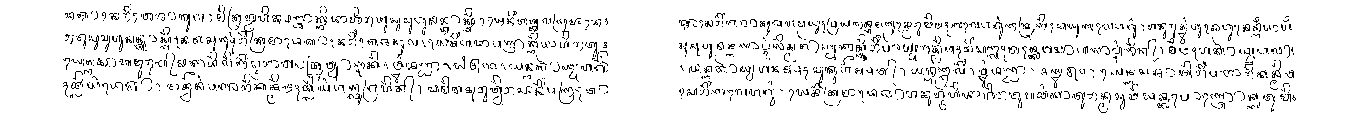
Figure 1 : Balinese manuscript with binarized ground truth image


Figure 2 : khmer manuscript with binarized ground truth image

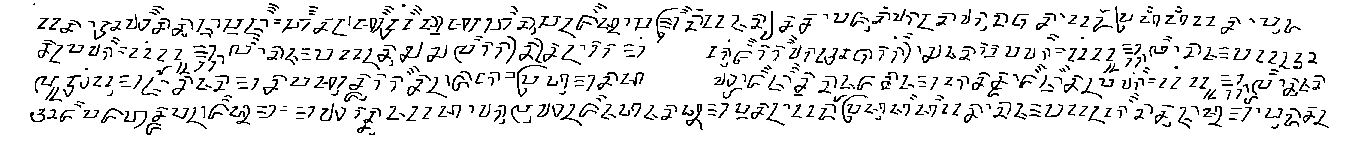
Figure 3 : Sundanese manuscript with binarized ground truth image
A.3 Track
This challenge has only one single track, binarization for a mixed collection of palm leaf manuscripts from Bali, Cambodia and Sunda.
A.4 Protocol
- Participants must submit a description of methods:
i) a maximum of one A4 page with a detailed description and
ii) a maximum of 200 words of a short summary
- Participants must submit the results of binarization for all images in the test set. For example: if the file name of the original image is ABCD01.jpg, then the binarized image should be named : ABCD01_binarized.png (or it can be in any other lossless image format).
- Participants must also submit a small, simple and complete (if use any library) executable package of their method implementation, with a clear user manual to run the binarization process for a given example of manuscript image.
A.5 Evaluation
Following the previous work [6] and the evaluation method from ICFHR competition [7], three metrics of binarization evaluation which are used in the DIBCO 2009 contest [9] will be used in the evaluation of the binarization task challenge. Those three metrics are F-Measure (FM), Peak SNR (PSNR), and Negative Rate Metric (NRM).
References
[1] R. Chamchong, C.C. Fung, K.W. Wong, Comparing Binarisation Techniques for the Processing of Ancient Manuscripts, in: R. Nakatsu, N. Tosa, F. Naghdy, K.W. Wong, P. Codognet (Eds.), Cult. Comput., Springer Berlin Heidelberg, Berlin, Heidelberg, 2010: pp. 55–64. http://link.springer.com/10.1007/978-3-642-15214-6_6 (accessed December 5, 2014).
[2] M.S.H. Naveed Bin Rais, Adaptive thresholding technique for document image analysis, in: IEEE, 2004: pp. 61–66. doi:10.1109/INMIC.2004.1492847.
[3] K. Ntirogiannis, B. Gatos, I. Pratikakis, An Objective Evaluation Methodology for Document Image Binarization Techniques, in: Eighth IAPR Int. Workshop Doc. Anal. Syst. 2008, IEEE, 2008: pp. 217–224. doi:10.1109/DAS.2008.41.
[4] D. Valy, M. Verleysen, K. Sok, Line Segmentation Approach for Ancient Palm Leaf Manuscripts using Competitive Learning Algorithm, in: 15th Int. Conf. Front. Handwrit. Recognit. 2016, Shenzhen, China, 2016.
[5] M.W.A. Kesiman, S. Prum, J.-C. Burie, J.-M. Ogier, An Initial Study On The Construction Of Ground Truth Binarized Images Of Ancient Palm Leaf Manuscripts, in: 13th Int. Conf. Doc. Anal. Recognit. ICDAR, Nancy, France, 2015.
[6] M.W.A. Kesiman, S. Prum, I.M.G. Sunarya, J.-C. Burie, J.-M. Ogier, An Analysis of Ground Truth Binarized Image Variability of Palm Leaf Manuscripts, in: 5th Int. Conf. Image Process. Theory Tools Appl. IPTA 2015, Orleans, France, 2015: pp. 229–233.
[7] J.-C. Burie, M. Coustaty, S. Hadi, M.W.A. Kesiman, J.-M. Ogier, E. Paulus, K. Sok, I.M.G. Sunarya, D. Valy, ICFHR 2016 Competition on the Analysis of Handwritten Text in Images of Balinese Palm Leaf Manuscripts, in: 15th Int. Conf. Front. Handwrit. Recognit. 2016, Shenzhen, China, 2016: pp. 596–601. doi:10.1109/ICFHR.2016.107
[8] M.W.A. Kesiman, J.-C. Burie, J.-M. Ogier, G.N.M.A. Wibawantara, I.M.G. Sunarya, AMADI_LontarSet: The First Handwritten Balinese Palm Leaf Manuscripts Dataset, in: 15th Int. Conf. Front. Handwrit. Recognit. 2016, Shenzhen, China, 2016: pp. 168–172. doi:10.1109/ICFHR.2016.39.
[9] M. Suryani, E. Paulus, S. Hadi, U.A. Darsa, J.-C. Burie, The Handwritten Sundanese Palm Leaf Manuscript Dataset From 15th Century, in: 14th IAPR Int. Conf. Doc. Anal. Recognit., Kyoto, Japan, 2017. doi:10.1109/ICDAR.2017.135.
[10] E. Saund, J. Lin, P. Sarkar, PixLabeler: User Interface for Pixel-Level Labeling of Elements in Document Images, in: IEEE, 2009: pp. 646–650. doi:10.1109/ICDAR.2009.250.