A. Balinese manuscript dataset
Firstly, we created the word annotated ground truth dataset of the manuscript, we asked a collaborative work between the Balinese philologists, students in informatics, and students in Balinese literature. They work together for segmenting and annotating the word in manuscript by operating ALETHEIA , an advanced document layout and text ground-truthing system. Each palm leaf manuscript image is then cropped based on each word polygon coordinate on XML file produced by ALETHEIA [8]. By using our collection of word-level annotated patch images, we applied binarization process to extract automatically all connected component found on the word patch images. The Balinese philologist will then annotate manually the segment of connected component that represent a correct glyph character in Balinese script based on annotation of that word. All the data that has been segmented and annotated at glyph character level will serve as our isolated glyph character dataset.
The dataset of isolated glyph characters contains about 19,383 samples of 133 classes. Number of samples for each class is different. Some classes are often used in our collection of palm leaf manuscripts, but some others are rarely used. For this competition, the dataset is partitioned into training and test subsets.
For the training subset, we will provide:
1. 10 original manuscript images with glyph character-level annotation (with the XML ground truth file format) (Fig. 8)
2. ± 19,000 glyph character-level annotated patch images (without any information about the manuscript images)
For the testing subset, we will provide:
1. 10 original manuscript images
2. 2 glyph character-level patch images per class as query test (133 classes x 2 glyphs = 266 glyphs)
All XML ground-truth files for glyph character-level annotation of the manuscript are presented in the next format, following the XML file format of ICFHR 2016 Handwritten Keyword Spotting Competition (H-KWS 2016) . A spotting area is defined by a rectangle with the TOP LEFT coordinate, the width and height.
| <?xml version="1.0" encoding="utf-8" ?> <glyphLocations dataset="collection"> <spot glyph="glyph1.jpg" image="page1.jpg" x="123" y="55" w="123" h="50" /> <spot glyph="glyph2.jpg" image="page1.jpg" x="553" y="97" w="100" h="59" /> <spot glyph="glyph3.jpg" image="page2.jpg" x="94" y="1197" w="244" h="62" /> <!-- The rest of the glyphs in the dataset --> </glyphLocations> |
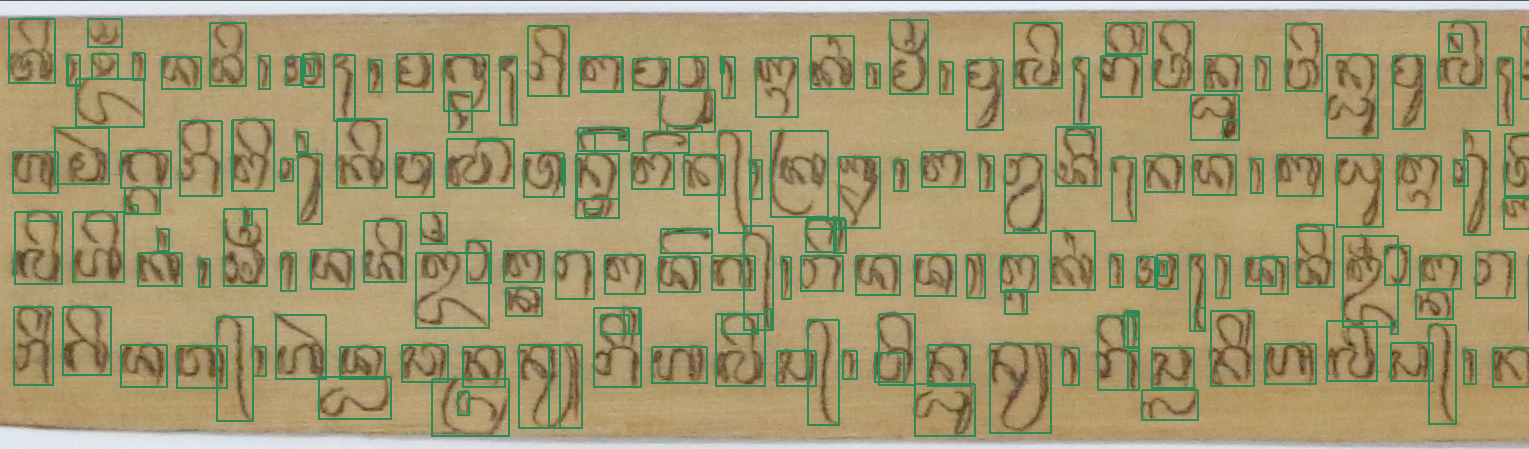
Figure 8. Examples of Glyph spotting ground truth file
B. Khmer manuscript dataset
In order to construct the ground truth for Khmer manuscript dataset, we developed our own tool to segment and annotate each individual character/glyph. By using this tool, we worked with computer science students from Institute of Technology of Cambodia and also from National Institute of Posts, Telecoms, and ICT to cooperatively perform the tasks. Coordinates of the polygon surrounding each character/glyph are dotted out manually. The ground-truthers are then prompted to input the correct Unicode or Unicode sequence as label for that character/glyph.
The patch images resulting from the area inside the rectangle bounding box of the dotted polygon of each character/glyph compose our Khmer manuscript dataset of approximately 130 classes. Just like the Balinese dataset, the number of samples in each class is not the same due to different appearance frequency of characters in the manuscript page and the fact that some characters/glyphs are more common than the others. For this dataset, the training and test subsets are provided as mentioned below.
For the training subset, we will provide:
1. 10 original manuscript images with glyph character-level annotation (with the XML ground truth file format)
2. ± 20,000 glyph character-level annotated patch images (without any information about the manuscript images)
For the testing subset, we will provide:
1. 10 original manuscript images
2. 2 glyph character-level patch images per class as query test (130 classes x 2 glyphs = 260 glyphs)
All XML ground-truth files for glyph character-level annotation of the manuscript are presented in the same XML format with Balinese manuscript dataset.
C. Access to the dataset
To download the dataset, please follow the instructions on the section "How to participate".
After registration to the competition, the login/password to access to the dataset will be sent by email.